
I just got a new laptop, an Asus ROG Zephyrus G15 GA503RM (2022), and of course, I’m timing the nCine compilation to see how much time it will make me save. 😉 Should you be interested in the first compilation benchmark article, it is available here.
As always, let’s start with the hardware and software details.
Hardware and software
Xiaomi Mi Notebook Pro (2017)
- Intel Core i7-8550U
- 16GB RAM, DDR4 2400 MHz, dual channel
- Samsung 970 EVO Plus NVMe SSD, 512GB
- NVIDIA GeForce MX150, 2GB GDDR5
Asus Zephyrus G15 (2022)
- AMD Ryzen 7 6800HS
- 16GB RAM, DDR5 4800MHz, dual channel
- Western Digital PC SN735 NVMe SSD, 1TB
- NVIDIA GeForce RTX 3060, 6GB GDDR6
OS, Compilers, and Tools
- Arch Linux 5.19.13 x86_64
- GCC 12.2.0
- CMake 3.24.2
- Ninja 1.11.1
Results
The nCine version is 2020.05.r115.g001bdce (or r422.001bdce) from the master branch, compiled with the default options:
NCINE_PREFERRED_BACKEND=GLFWNCINE_BUILD_TESTS=ONNCINE_BUILD_UNIT_TESTS=OFFNCINE_BUILD_ANDROID=OFF
As usual, the tests have been conducted by running the compilation process multiple times and recording the best times.
In the Configure phase, CMake is invoked to configure the project and generate Ninja files.
time cmake -S nCine -B nCine-build -G Ninja &> /dev/null
In the Build phase, ninja is invoked to build the project with all or just one core.
time ninja &> /dev/null
time ninja -j1 &> /dev/null
In both phases, I redirected all the output to /dev/null to save the console printing time.
Tables and charts
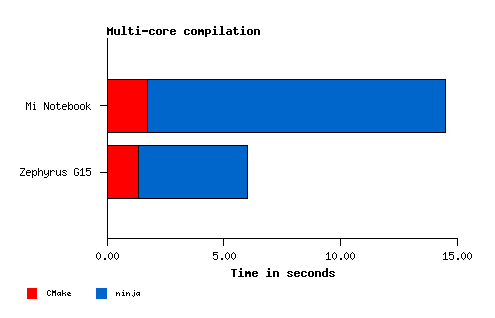
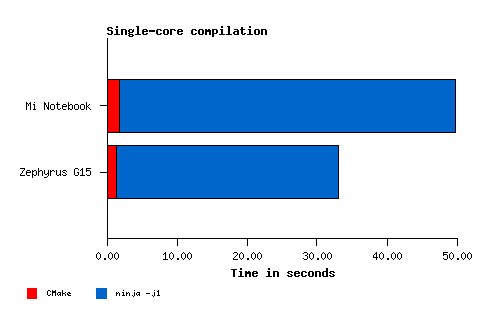
| Mi Notebook | Zephyrus G15 | Ratio | |
|---|---|---|---|
| Configure Ninja | 1.715 s | 1.330 s | 1.289x |
| Build Ninja | 12.774 s | 4.683 s | 2.727x |
Build Ninja -j1 | 48.141 s | 31.731 s | 1.517x |
Conclusions
The Ryzen 6800HS, with its eight Zen 3+ cores, smashes the old Mi Notebook Pro, with its four Kaby Lake R cores, compiling the nCine in one-third of the time! 💪 I’m sure that the faster SSD and RAM also help in this test.
I was expecting a bit more from the single-core compilation results, but completing the compilation in roughly 65% of the time is not bad.
These results are very close to what we can expect by running Cinebench R23, for example.
The smaller difference can be found in the configuration phase: the new laptop still needs 3/4 of the time of the old one. CMake is surely using just one core and maybe hitting an I/O bottleneck, but a small improvement can still be found.
I hope you enjoyed this benchmarking article as much as I am enjoying my new machine. 😉